都道府県別の平均寿命を地図上にマッピングしてみました。
目次
1. 実行環境
OS : Windows 10 64bit
Python : 3.6.3
folium : 0.8.3
folium の詳しい使い方はこちらを参照ください。
2. 可視化するデータについて
読み込むデータはname(都道府県名), data(平均寿命), data1(円の半径), lat(緯度), lon(経度)のデータが入っています。
都道府県別の平均寿命のデータと、都道府県別の経度・緯度のデータをExcel上で結合しました。
なお、name(都道府県名)はデータの視認性を挙げるために付記しているもので、python上では使用していません。
後述しますが、CSVファイルは、 UTF-8(コンマ区切り)(.csv)です。UTF-8にしないとエラーになるので注意が必要です。

3. Pythonのスクリプト
import folium
import pandas as pd
#foliumのバージョンを表示
print( "folium version is {}".format(folium.__version__) )
#初期設定とか
datafile = "mapdata.csv" #読み込むデータ名を指定
lat, lon = 34.4586, 133.2295 #画面の中心の経度・緯度を指定
zoom_start = 5 #拡大率を指定
webfile_name = "folium_test.html" #エクスポートするHTMLファイル名を指定
m = folium.Map(location=[lat, lon], zoom_start=zoom_start)
X = pd.read_csv(datafile) #データ読み込み
for index, r in X.iterrows():
folium.CircleMarker(
location=[r.lat, r.lon],
radius=r.data1,
color='#3186cc',
fill_color='#3186cc',
).add_to(m)
m.save(webfile_name)
4. 出力されたHTMLファイル
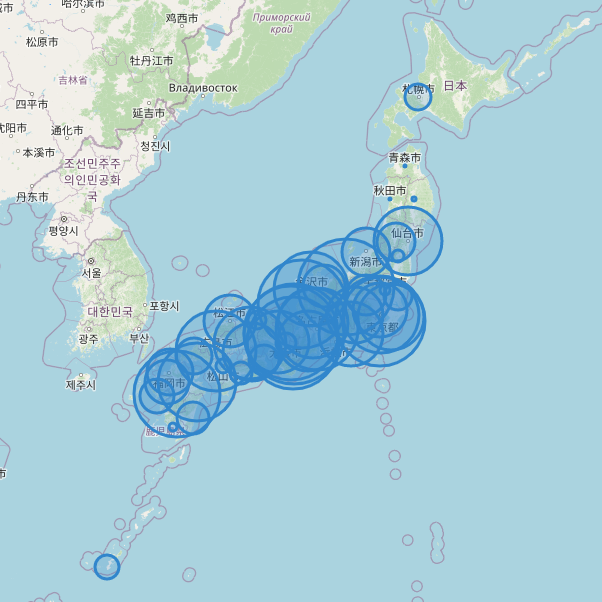
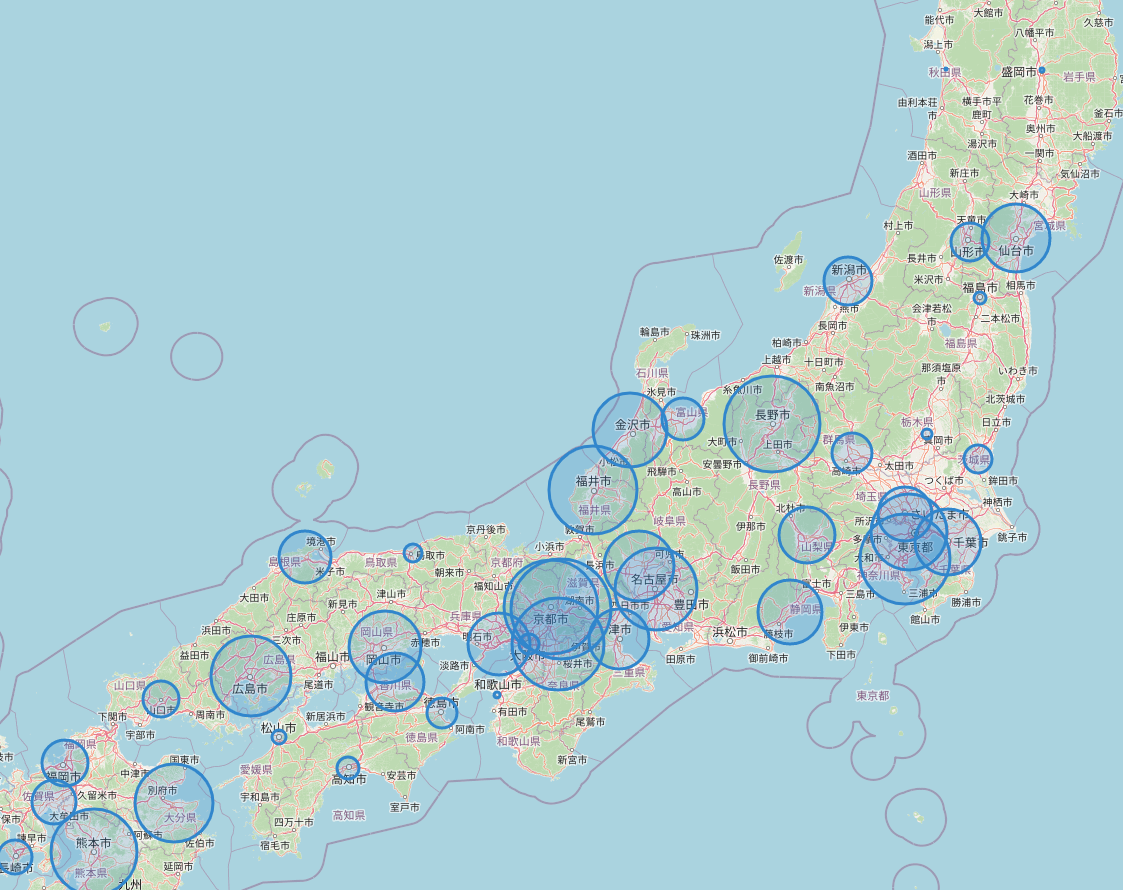
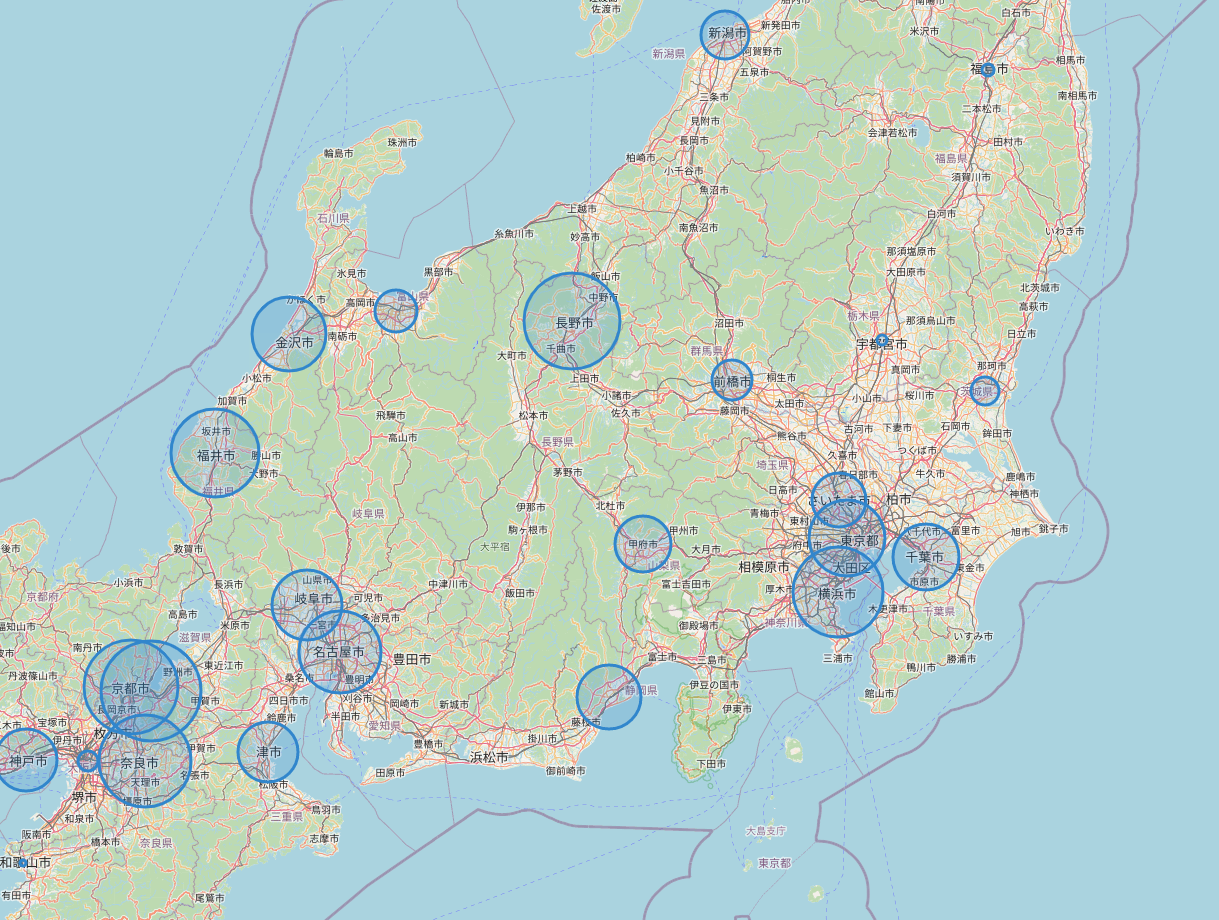
5. 結論
都道府県平均寿命を円グラフで表示するのはいまいちわかりにくく、可視化としてセンスがありませんでした。
とは言え、foliumの簡単な使い方がわかってよかった。
6. 補足 : pandasでread_csv時にUnicodeDecodeErrorが起きた時の対処方法
pandasでCSVファイルを読み込む場合、以下のようなエラーが発生しました。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
文字コードが原因らしく(たしかに日本語が混在しているCSVを使用してます)、Excel作成のCSVは文字コードが「shift-jis」らしいので、以下のようにread_csvの引数にエンコード(shift-jis)を指定しました。
X = pd.read_csv(datafile, encoding="shift-jis")
それでもエラーが発生しました。
UnicodeDecodeError: 'shift_jis' codec can't decode byte 0x80 in position 5: illegal multibyte sequence
CSVファイルを一度、Notepadでエンコードを指定して別名保存してみる、なども試してみましたが、解決せず。
さらに調べていると、ExcelでCSVを保存するときに、UTF-8を指定して保存できることがわかりましたので、そちらを試しました。
以下のように、フォーマットを指定するプルダウンメニューにCSV UTF-8 [カンマ区切り] (*.csv)という選択肢がありますので、こちらを選択して保存します。
これで、エラーが発生しなくなりました。read_csvの引数にエンコードを指定する必要もありません。
![]()

コメント